|
I am a Research Engineer at Meta in Zurich (Switzerland), where I work on Computer Vision and Machine Learning with a focus on 3D Perception. I did my PhD at the University of Trento (Italy). My advisors were prof. Elisa Ricci (University of Trento) and dr. Samuel Rota Bulo' (Meta). |

|
|
|

|
Andrea Simonelli, Norman Müller, Peter Kontschieder ICCV, 2025 (oral presentation) Project page We introduce a 3D interactive segmentation method that consistently surpasses previous state-of-the-art techniques on both in-domain and out-of-domain datasets. Our simple approach integrates a voxel-based sparse encoder with a lightweight transformer-based decoder that implements implicit click fusion, achieving superior performance and maximizing efficiency. Easy3D demonstrates substantial improvements on benchmark datasets, including ScanNet, ScanNet++, S3DIS, and KITTI-360, and also on unseen geometric distributions such as the ones obtained by Gaussian Splatting. |
|
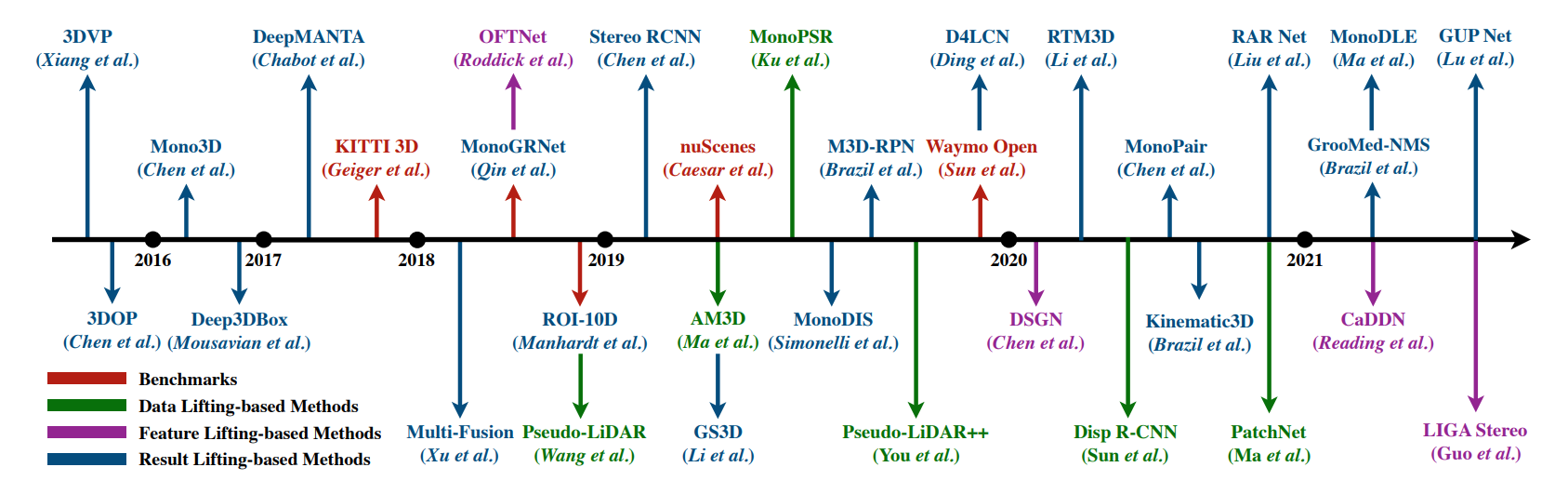
Xinzhu Ma, Wanli Ouyang, Andrea Simonelli, Elisa Ricci TPAMI, 2024 Paper link 3D object detection from images, one of the fundamental and challenging problems in autonomous driving, has received increasing attention from both industry and academia in recent years. Benefiting from the rapid development of deep learning technologies, image-based 3D detection has achieved remarkable progress. Particularly, more than 200 works have studied this problem from 2015 to 2021, encompassing a broad spectrum of theories, algorithms, and applications. However, to date no recent survey exists to collect and organize this knowledge. In this paper, we fill this gap in the literature and provide the first comprehensive survey of this novel and continuously growing research field, summarizing the most commonly used pipelines for image-based 3D detection and deeply analyzing each of their components. |

|
Norman Müller, Andrea Simonelli, Lorenzo Porzi, Samuel Rota Bulò, Matthias Nießner, Peter Kontschieder, CVPR, 2022 Project page From just a single view, we learn neural 3D object representations for free novel view synthesis. This setting is in stark contrast to the majority of existing works that leverage multiple views of the same object, employ explicit priors during training, or require pixel-perfect annotations. Our method decouples object geometry, appearance, and pose enabling generalization to unseen objects, even across different datasets of challenging real-world street scenes such as nuScenes, KITTI, and Mapillary Metropolis. |
|
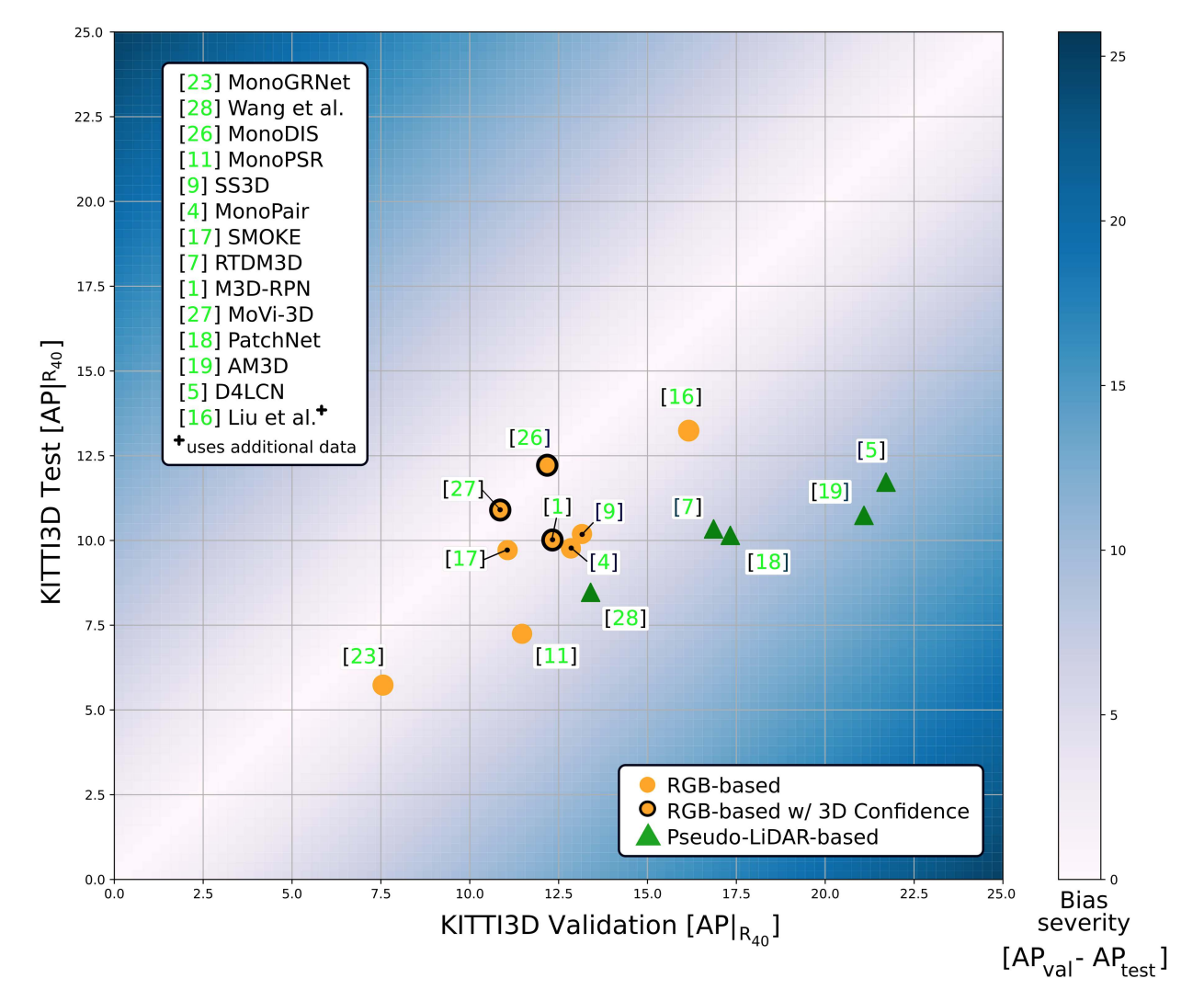
Andrea Simonelli, Samuel Rota Bulò, Lorenzo Porzi, Peter Kontschieder, Elisa Ricci ICCV, 2021 Paper link We closely analyze a novel branch of 3D Object Detection methods from Images i.e. Pseudo-LiDAR based methods. We identify a flaw in their widely popular training protocol, which introduces a distorted perception about their performance. On top of this, we propose to introduce a novel Absolute and Relative 3D Confidence module which is demonstrated to increase 3D Detection performance substantially. |
|
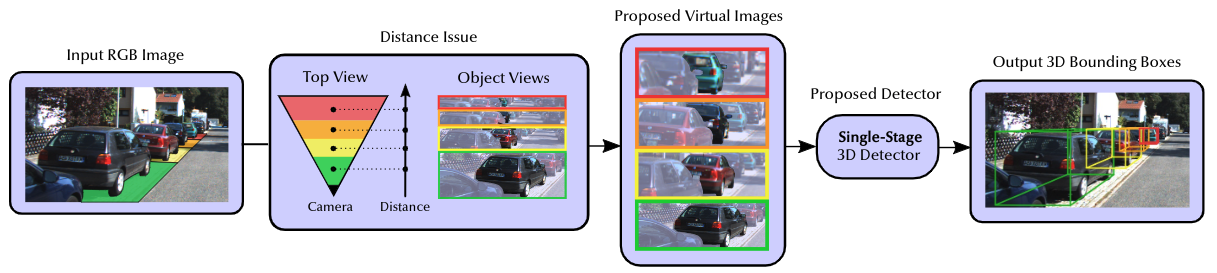
Andrea Simonelli, Samuel Rota Bulò, Lorenzo Porzi, Elisa Ricci, Peter Kontschieder ECCV, 2020 Paper link We propose to perform the detection, instead of on the usual full-resolution image, on a series of Virtual Views. Virtual Views make the appearence of the objects invariant with respect to distance, easing the overall task. We also propose a single-stage, lightweight architecture called MoVi-3D. We achieve state-of-the-art results on the popular KITTI3D benchmark. |
|
Andrea Simonelli, Samuel Rota Bulò, Lorenzo Porzi, Manuel Lòpez Antequera, Peter Kontschieder TPAMI, 2020 Paper link We extend our previous ICCV19 work to the multi-class scenario. In particular, we apply the MonoDIS detector to the challenging nuScenes dataset, achieving comparable results with a LiDAR baseline. In this work we also report updated scores on KITTI3D. |
|
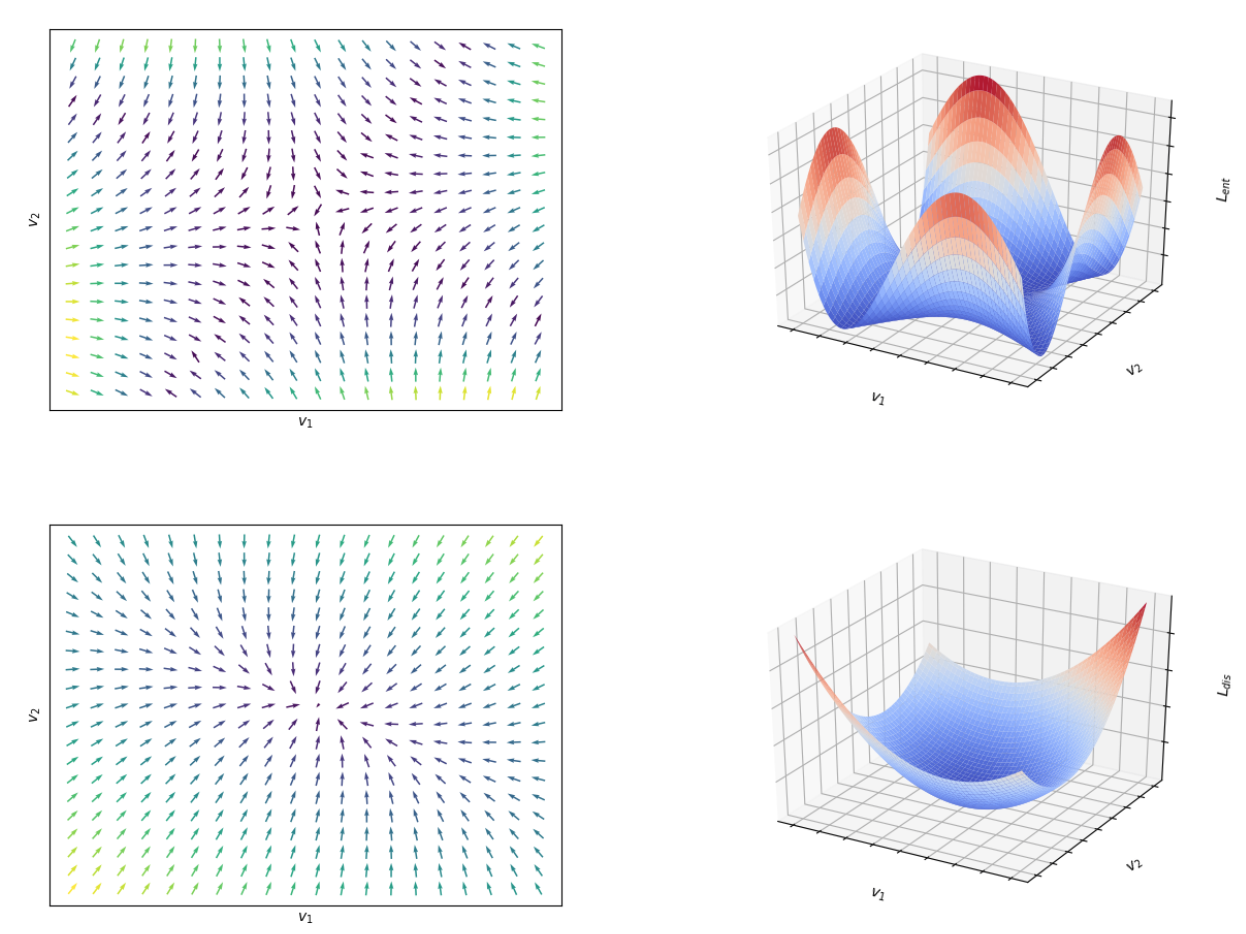
Andrea Simonelli, Samuel Rota Bulò, Lorenzo Porzi, Manuel Lòpez Antequera, Peter Kontschieder ICCV, 2019 Paper link We propose a disentangling transformation which simplifies the training dynamics in the presence of losses with complex interactions of parameters, sidestepping the issue of balancing independent regression terms. We also propose a self-supervised 3D confidence which is very useful to understand the quality of the predicted 3D bounding boxes. In addition, we resolve a flaw in the (now deprecated) KITTI3D metric which affected all the previously published results. Our proposed metric is now the official KITTI3D metric, used to evaluate all methods on the KITTI3D benchmark. |

|
Andrea Simonelli, Francesco De Natale, Stefano Messelodi, Samuel Rota Bulò ICIP, 2018 (Oral presentation) Paper link We propose a simple method for fine-grained recognition that exploits a nearly cost-free attention-based focus operation to construct an ensemble of increasingly specialized Convolutional Neural Networks. |
|
|
| 1st Workshop on 3D Object Detection from Images, ICCV 2021 |
|
|
 |
Winner team of the nuScenes 3D Object Detection Challenge Camera Track, CVPR 2019 |
|
|
 |
Advanced Algorithms Teaching Assistant, prof. Elisa Ricci and dr. Samuel Rota Bulò, Spring 2020 |
|
The source code for this website has been taken from this nice repo. Last update: April 2025. |